RabbitMQ和Kafka有何不同?何時該選用哪種產品?
Message broker主要有分為兩類,分別是memory based及log based, Redis或RabbitMQ作為broker的是memory based的,而log based最有名的, 就是Kafka。這兩種有何不同呢?何時又該選用哪種message queue?
這篇文章首先會討論message broker普遍的基本特性及用法, 然後再探討兩種broker內部設計的不同,最後就可以比較在各種特性上,兩者的不同。
在上篇文章什麼是message queue? 優點及使用場景中, 看完了為何要使用message queue之後,今天要討論兩類message broker的差異,分別是memory based及log based,

基本特性
Message borker最基本的操作就是produce跟consume,一個產生message,一個消耗message, 此時我們可以問的幾個問題如下:
Multiple consumers
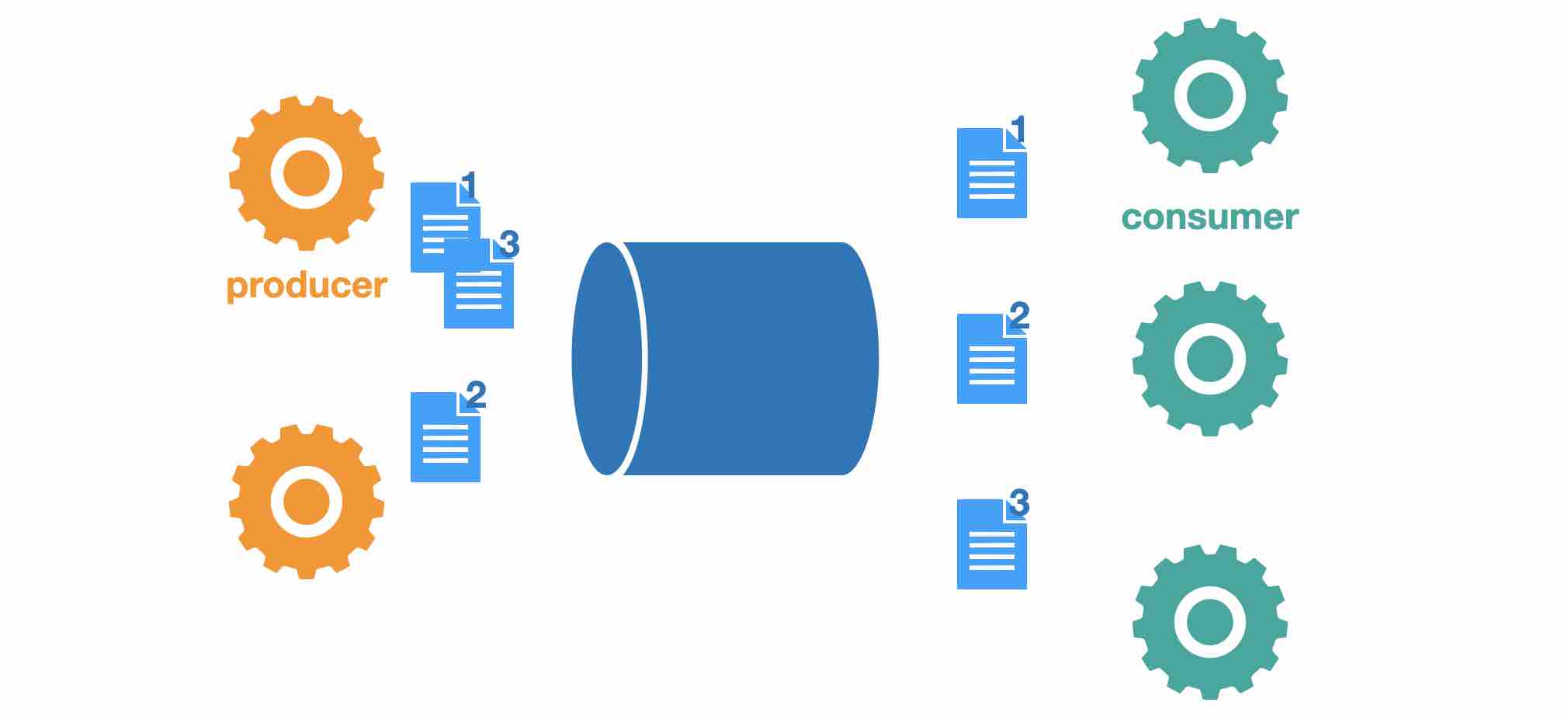
當有多個consumer時,每個message會被處理多次嗎?還是只會被其中一個consumer處理到一次?
Load balancing
每個message只會被其中一個consumer處理到,所以你可以指派任意多個consumer去consume一個topic, 當你想要並行處理你的工作時,這會非常有用。
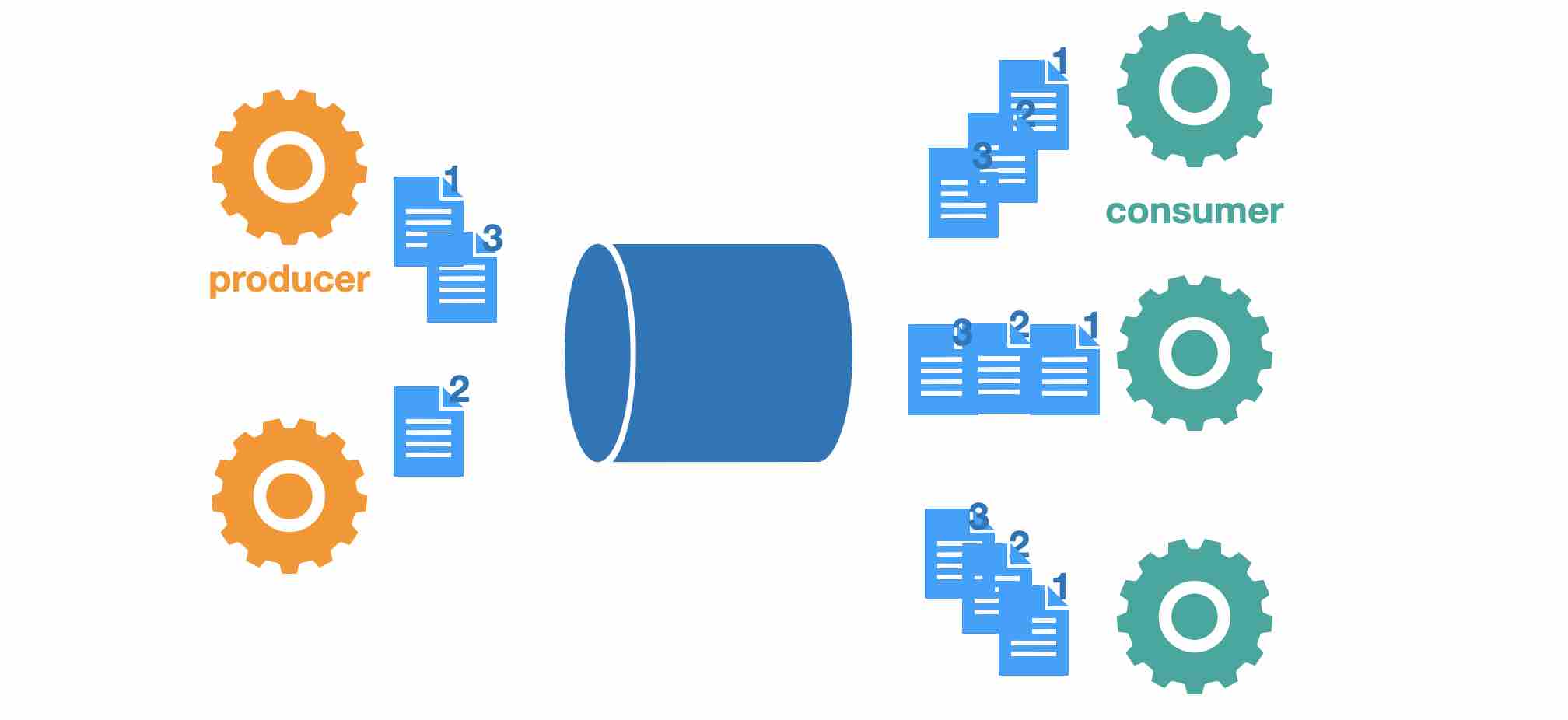
Fan-out
每個message會被送到所有的consumer去處理,像是broadcast,可以用在當你的message需要到各個不同的系統時, 比如說一筆交易的資料,需要被送到data warehouse保存、送到BI分析給老闆看、送到使用者的系統來更新他的交易資訊頁面。
Persistence
當broker掛掉時,已經發送過來的messsage會消失嗎?還是等到broker重啟之後,會再重新發送?
就是顧名思義,producer的每個message,是否會確保送到consumer那邊,broker掛掉,message還會不會在。 不過consumer有沒有處理好這個message又是另一回事了(見下段Acknowledgements)。
Acknowledgements
當consumer工作到一半掛掉時,如何確保每個message已經被完整地處理好了呢?
因為consumer也可能隨時會掛掉,可能在收到訊息之前,或收到訊息但工作到一半時, broker為了確保訊息有好好地到達,會使用acknowledgement, acknowledgement就是必須由consumer告訴broker,他已經收到message,broker可以將他從queue中移除了, 至於ack的時機不同會導致訊息被處理的次數的保證的不同。
At most once
先ack,再處理訊息,如果在處理到一半時掛掉,這個訊息就沒被完整處理到了, 因為已經ack了,broker已經把訊息從queue中移開,不會再發送這個訊息出來, 所以最差的情況就是沒被處理到,正常的情況就是處理一次,而且最多一次,此為at most once。
//consumer first ack the message and the process
function (message) {
queue.ack(message)
essage.ack()
}
At least once
想反地,先處理訊息再ack,如果在處理到一半時掛掉, 因為還沒ack,broker會再發送這個訊息出來, 所以最差的情況就是訊息被處理到多次,正常的情況就是處理一次,而且至少一次,此為at least once。
//consumer processes the message first and then ack it
function (message) {
process(message)
message.ack()
}
Internal Design
現在就來看看message system的內部設計,如此一來就可以知道各個系統的特性以及該如何回答上面的問題,
Memory based
這類系統顧名思義,主要使用memory作為message存放的地方,當consumer ack了某個信息後, 就把它刪掉了,完全不留痕跡。當然很多系統也可以透過設置,決定要不要將信息寫到硬碟上, 不過主要是用來做recovery的,確保broker本身掛掉時,message不會丟失, 當確認了message已經成功抵達了它要到的地方後,一樣會把它刪掉。
此類系統著重的是message從producer到consumer的過程,而不是留下一個永久的狀態或結果。
而信息的傳送是由broker主動push給consumer的。
Log based
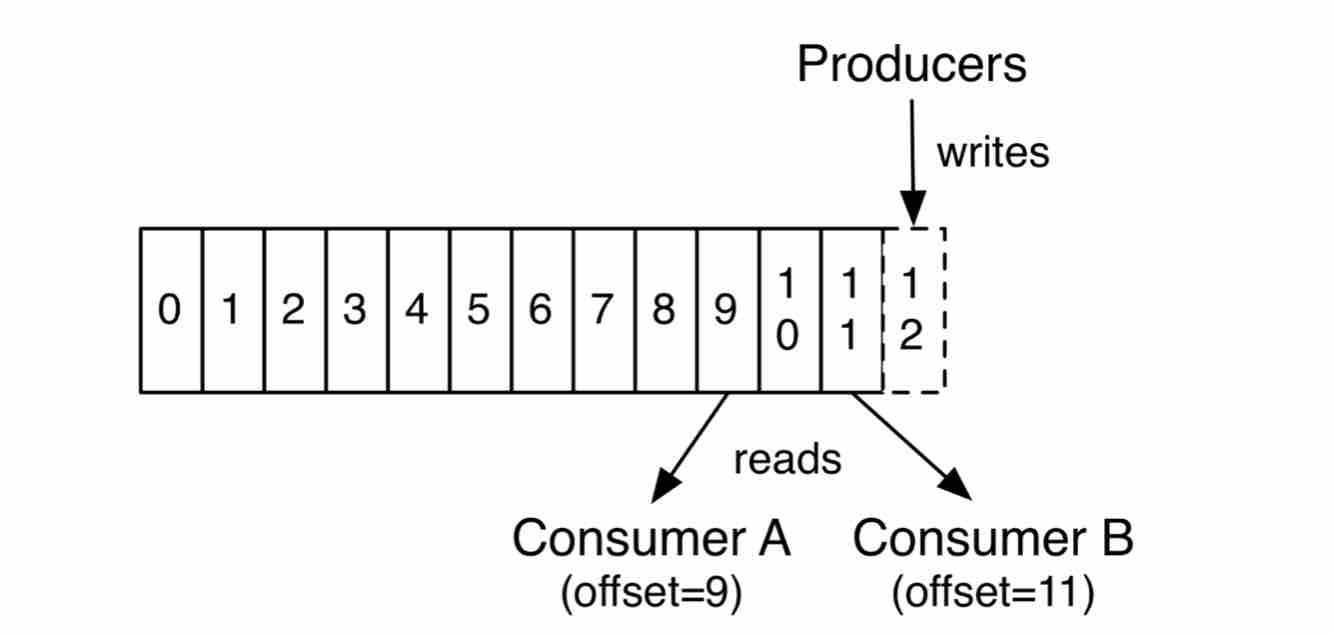
而log based的系統則是相反,只有要message進來,就都寫到硬碟上,是一個append only log,
當consumer要消耗信息時,就是讀取檔案上的資料,讀到盡頭了就等通知,
等有新的資料繼續被append到檔案中,有點像是Unix tool tail -f 的感覺。
此時,信息的傳送consumer去向brokerpull。
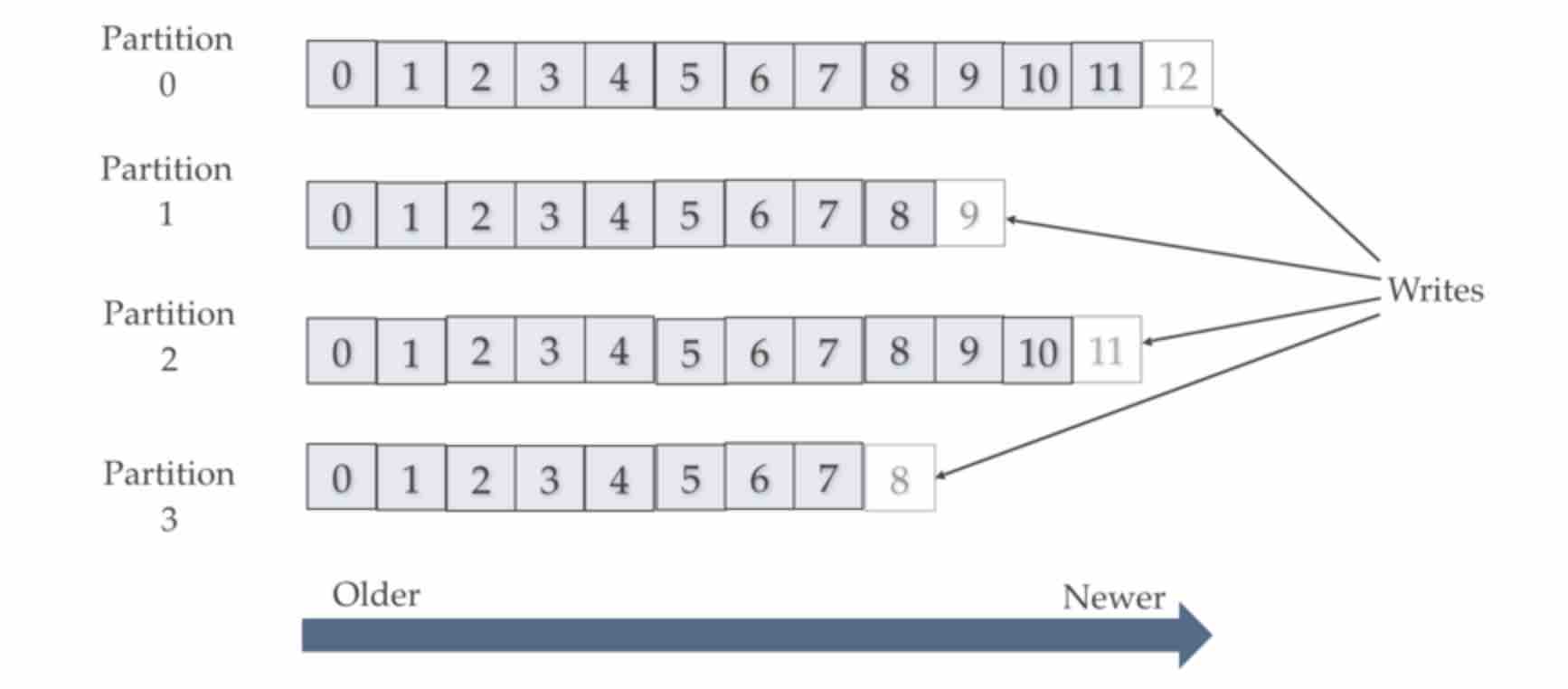
為了不讓寫入的速度被限制一個硬碟上,需要將一個topic的log partitioned, 每個partition由一台機器負責,可以獨立地讀寫。
Comparison between RabbitMQ and Kafka
終於可以來看看兩者的比較拉~ 首先奉上一個表格,再來一點一點詳細討論!
| 特性 | RabbitMQ | Kafka |
|---|---|---|
| Load Balancing | Yes | Yes, but limited |
| Fan-out | Yes, through exchabge binding | Yes |
| Persistence | Yes, through configuration | Yes |
| Inorder delivery | Yes, conditionally | yes, per partition |
Load Balancing
- Memory based: 自然地support了load balancing,當有message時, broker輪流地向跟他有建立連結的consumer推送信息,就達成了load balancing的效果, 越多consumer,就可以平行處理越多的工作。
- Log based: 無法天生支援load balancing,因為每個consumer彼此是各自獨立的,分別從頭、 或從某個地方開始讀取log檔案,所以想達成load balancing,是透過partition的方法:
假設我現在有一個topic,並且將它partition成三份,此時就可以assign三個consumer給他, 看起來就像是這一個topic的message被分給三個consumer,而實際上是每一個partition對應到一個consumer, 所以!可以同時平行處理這個topic的consumer的數量,也就會是partition的數量。
Fan-out
- Memory based: 需要透過額外的設計才能達成,RabbitMQ implememt的AMQP協議, exchange binding可以實現pub-sub的patter。
- Log based: 自然地support fan-out,每個consumer對log檔案想讀哪就讀哪,想重複讀幾次就讀幾次。
Persistence
- Memory based: 透過設置,可以同步將message寫入硬碟,確保不會丟失,不過就只保存到當consumer成功消耗之前。
- Log based: 如前面所述,每個message都會寫入硬碟,除非你說要刪掉它,不然就會一直在。
Inorder delivery
- Memory based: 無法保證message一個一個按照順序的被處理,除非每一個topic只有一個consumer。
- Log based: 每個partition上的message,一定是被consumer做一個sequential read的動作, 所以信息一定會被按照順序讀取,但不同partition之間就沒有順序的保證,他們基本上是獨立的。
Use cases
最後就來看看在哪些場景比較適合使用哪一種產品吧!根據以下幾個問題及情境分別回答:
- 是否需要被保存下來?
- 工作昂不昂貴?
- 順序重要嗎?
是否需要被保存下來?
如果你想要message被保存下來,那就用log based的messaging system,保存下來有哪些好處呢?
- 可以肆無忌憚地去consume message,可以去嘗試、做實驗,不用怕message會不見,
- 各種event sourcing的好處,有興趣的可以google它看看~
工作昂不昂貴?
如果處理一個message的工作量是很大的,需要耗費很多時間才能做完,你可以比較不會想用log based的產品,為什麼呢?
- 它無法使用大量的consumer來平行地處理所有的工作,因為可以平行工作的consumer的數量受限於partition的數量
- 在一個partition裡,只要有個message需要耗費很多的時間,就會造成塞車,也就是head of line blocking。
順序重要嗎?
有些類型的message彼此是獨立不相干的,被處理順序是如何並不重要,就沒一定要使用log based的產品, 但當你需要保留message的順序時,唯有log based的messaging system可以給你保證,不過只限定於同個partition。
有哪些例子是順序重要的呢? 比如說對一個使用者的帳戶餘額做加減乘除的運算,順序不同結果就不同, 但你可以使用user id作為partition key,則在每一個partition裡保持對的順序就好,不同的partition間的順序就不重要了。
感謝你閱讀到這邊~ 希望以上的內容對你有一丁點的幫助,掰掰~ 👋




