Pagination 是什麼?API 分頁設計完整指南
Pagination(分頁)是什麼?為什麼 API 需要分頁?完整介紹 Offset、Cursor 兩種分頁做法的差異與實作方式,讓你的 REST API 回應更快、體驗更好。
為何要Pagination
一個response如果資料太多,回應太慢,一定會造成使用者的體驗不佳,進而流失用戶, 而pagination就是使reponse回應速度的加快的做法之一。
比如說你在用instagram,在探索頁面中一眼看到的貼文可能只有10幾篇, 此時你就不需要一次抓回來30篇甚至是更多的貼文資料,藉此來減少用戶等待的時間, 只有當用戶繼續將螢幕往下滾時,再抓取下一個10幾篇的資料就好。
以下來看看兩種Pagination的做法,offset及keyset:
Offset Pagination
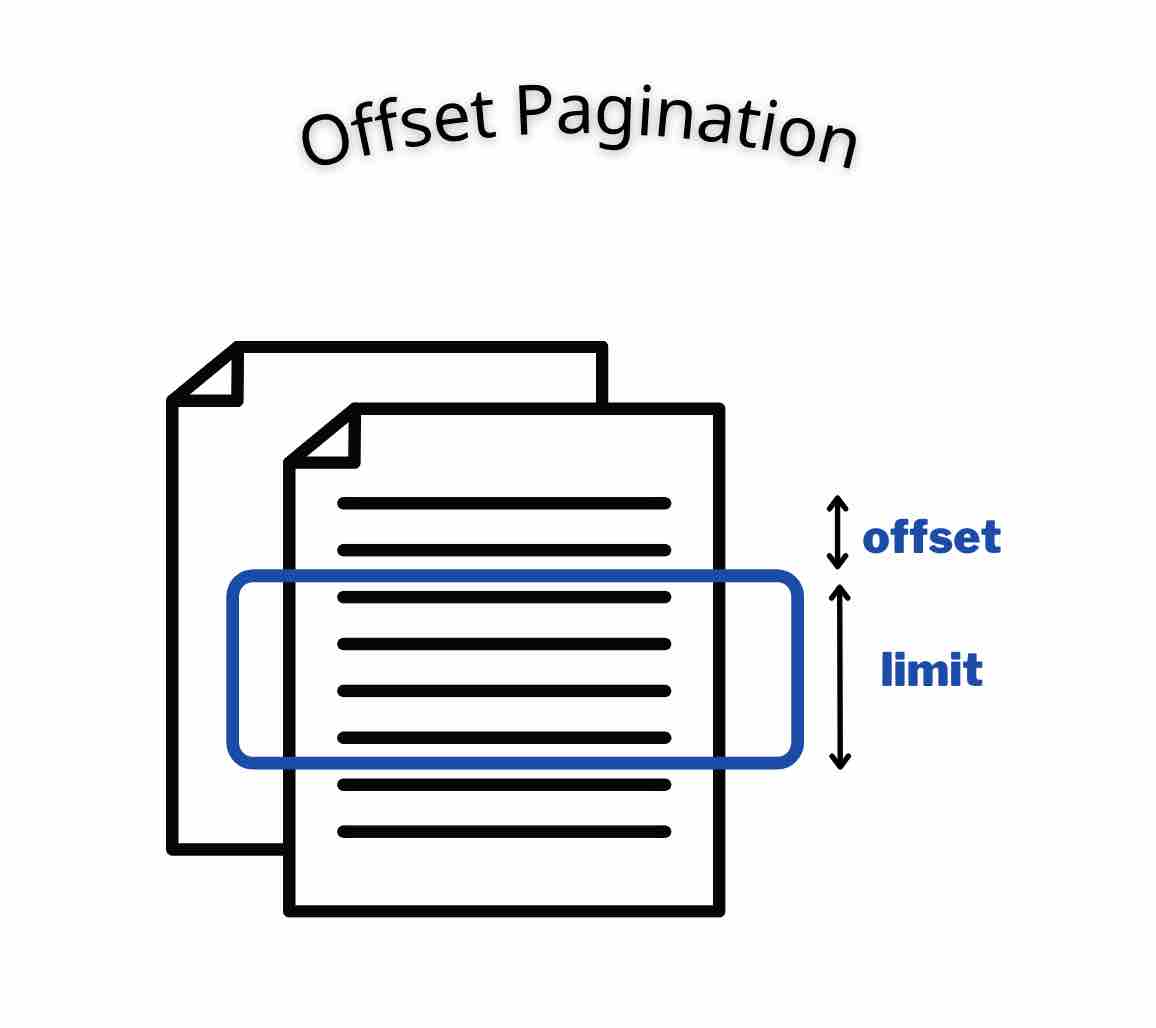
最基本的做法就是使用offset及limit,一樣的概念在SQL語法中也可以看到:
SELECT * FROM items LIMIT 20;
而在HTTP API裡,則會像是這樣
curl http://api.exmaple.com/items?offset=0&limit=10
也有一些服務會使用其他的名字,例如Elasticsearch用的from及size,都是代表一樣的意思,
從第幾則資料開始(offset、from)算,總共抓取幾則資料(limit、size)。
offset pagination可能的問題
- 當offset很大時,比如說offset=1000000,API server必須scan一百萬的資料,效能不彰。
- 再來就是當你的資料持續再增加時,可能會造成一些混亂,以下面的例子為例:
-
GET /items?offset=0&limit=10 - 增加了5筆資料
- 再一次
GET /items?offset=0&limit=10,結果其中5筆是第一次query裡已經有出現的了
Keyset Pagination
不是使用offset,而是使用某個key作為指定的起始點,比如說created_at,HTTP request看起來可能像是這樣
curl http://api.exmaple.com/items?limit=10&created_at:lte:2022-04-10T00:00:00
只抓取創建時間比2022-04-10T00:00:00還要早的資料,想翻頁時, 就將created_at:lte的時間指定為上一次回傳的最後一筆資料的created_at就好了,如此一來, 就不會有後來新增的資料跑進來的問題了。
而且通常所使用的key在資料庫中會建立索引,也可以避免上述使用offset造成的large database scan的問題。
這是RESTful API一系列文章中的一篇,想了解更多關於RESTful API及HTTP的,可以看這篇目錄:
感謝您的閱讀~期待下次見!




